
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 정보처리기사
- java
- pds
- javascript
- 웹앱
- ensemble
- regressor
- sklearn
- crawling
- AWS
- request
- 자바스크립트
- pandas
- Intellij
- Req
- list
- BeautifulSoup
- lombok
- 정보처리기사필기
- 백준
- dataframe
- springboot
- 비전공자
- 머신러닝
- BS
- APPEND
- 정처기
- SOUP
- 크롤링
- 자바
- Today
- Total
No sweet without sweat
[Machine Learning] - 서울시 구별 CCTV 현황 분석하기 (numpy, pandas, matplotlib.pyplot) 본문
[Machine Learning] - 서울시 구별 CCTV 현황 분석하기 (numpy, pandas, matplotlib.pyplot)
Remi 2022. 9. 2. 01:23plt.scatter(data_merge['소계'], data_merge['인구수']) plt.show()문제
- 서울시 각 구별 CCTV수 파악
- 인구대비 CCTV 비율을 파악해서 순위매기기
- 인구대비 CCTV의 예측치를 확인하고, CCTV가 부족한 구 확인
1. 사용할 라이브러리 임포트하기
- numpy : 고성능 과학계산을 위한 라이브러리, 다차원 데이터 다루는데 용이
- pandas : 데이터를 표 형식으로 보여줌 1, 2차원 데이터(DataFrame)
- matplotlib : 데이터 시각화
2. CSV 파일 읽어오기
1) 서울시 구별 CCTV

cctv_seoul변수에 담고 head()로 기본값인 상위 데이터 5개 출력
2) 서울시 인구현황
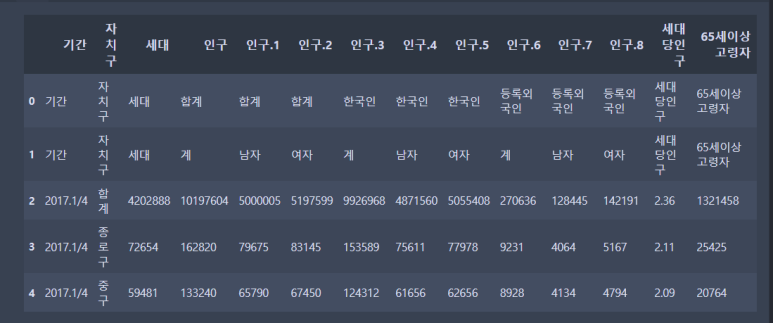
데이터 전처리
1) 칼럼명 수정
- cctv데이터 컬럼명 수정
- 기관명 -> 구별
- rename({바꿀값 : 바뀔 값}) : 컬럼명 바꾸기
- cctv_seoul.rename(columns={cctv_seoul.columns[0]:"구별"}) 이건 출력만
- 저장을 위해서는 inplace or 변수에 담아주기
cctv_seoul.rename(columns={cctv_seoul.columns[0]:"구별"}, inplace = True)이렇게 inplace에 true로 입력에 저장해주거나 새로운 변수에 담아줘야한다.
그러나 inplace가 안되는것도 있기에 독스트링(shift + Tab)으로 확인한다

다음과 같이 '소계'로 변경된 칼럼을 확인할 수 있습니다.

2) population 데이터 중 B, D, G, J, N 칼럼만 가져오기
seoul_population = pd.read_excel('population_in_Seoul.xls',
header = 2,
usecols = 'B,D,G,J,N')
seoul_population.head()- hedaer : 시작할 행(row) 시작
- usecols : 가져올 columns 선택


csv를 확인해보셔서 위 칼럼 A, B, C, etc 확인할 수 있습니다
2행부터 시작하면 3행부터 출력되기에 header =2 로 설정했습니다.
3) population 칼럼명 변경
# 자치구 -> 구별
# 계 -> 인구수
# 계.1 -> 한국인
# 계.2 - > 외국인
# 65세 -> 고령자
seoul_population.rename(columns={
seoul_population.columns[0] : "구별",
seoul_population.columns[1] : "인구수",
seoul_population.columns[2] : "한국인",
seoul_population.columns[3] : "외국인",
seoul_population.columns[4] : "고령자"}
, inplace = True)변경값 확인 :

4) CCTV가 가장적은 구와 가장 많은 구를 확인
- 칼럼안에 값을 기준으로 정령
- 기본 정렬값은 오른차순

- cctv가 가장 많은 구 확인
cctv_seoul.sort_values(by ="소계",ascending=False)출력 값:

- 최근 3년동안 CCTV 증가율 파악
1) 변수 생성
cctv_seoul['최근 3년 생성 갯수'] = cctv_seoul['2014년']+
cctv_seoul['2015년']+
cctv_seoul['2016년']출력 값 :
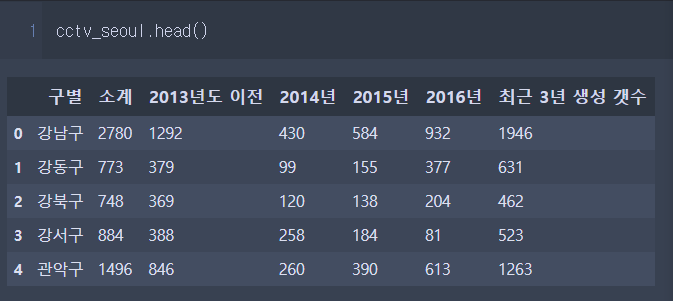
1-1) 변수생성
2) 출력
출력 값:

- 서울시 인구 데이터 파악
1) 행과 열의 갯수 출력
cctv_seoul.shape seoul_population.shape출력값:
(25, 8)
(27, 5)
2) 칼럼명 확인
cctv_seoul.columns seoul_population.columns출력 값:


3) 중복된 값 제거

3-1 ) set 집합자료형 함수 이용
(1) 인구수
set(seoul_population['구별'].unique())-set(cctv_seoul['구별'].unique())set은 순서가 없고 중복을 허용하지 않는다.
출력 값:

(2) 씨씨티비 개수
set(cctv_seoul['구별'].unique())-set(seoul_population['구별'].unique())출력 값:

3-2) 인구수에서 nan 값과 합계 값이 있는 행 삭제
seoul_population[seoul_population['구별'] == "합계"].index- Boolean 인덱싱을 통해 합계 값이 있는 행 출력
출력:
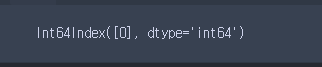
4) drop함수를 통한 합계 행 제거 - 0번째 행 확인 (drop(행번호)
seoul_population.drop([0], inplace =True)4-1) 결측치 제거 - isnull
del_index = seoul_population[seoul_population['구별'].isnull()].index
seoul_population.drop(del_index,inplace=True) seoul_population5) 구별 칼럼을 기준으로 데이터 합치기
data_merge = pd.merge(cctv_seoul, seoul_population, on ="구별")|
데이터 프레임을 합치는 함수
- concat : 행, 열을 기준으로 데이터 프레임를 합침
- merge : 행, 열 속의 값 기준으로 데이터 프레임을 합침
|
출력 값:

6) 인구대비 CCTV비율
- '인구대비 CCTV 비율' 칼럼 생성
- data_merge에서 소계 / 인구수 값 대입
data_merge['인구대비 CCTV 비율'] = data_merge['소계']/data_merge['인구수']
data_merge.sort_values(by='인구대비 CCTV 비율' , ascending=False).head()
출력값 :

7) 인구대비 CCTV의 예측치를 확인하고 CCTV가 부족한 인구 확인
data_merge.set_index('구별', inplace=True)- set_index('인덱스로 만들 칼럼 이름')
8) 인구수 대비 CCTV 수 시각하
출력 값:

8-1) 그래프로 시각화
from matplotlib import rc rc('font', family ='Malgun Gothic')
plt.figure(figsize = (15,8)) plt.barh(data_merge.index , data_merge['인구대비 CCTV 비율']) plt.show()
출력 값:

- 값 저장
data_merge.sort_values(by = '인구대비 CCTV 비율', ascending=False, inplace =True)9) 인구수 대비 CCTV 비율 예측 값 만들기
from sklearn.linear_model import LinearRegression linear_model = LinearRegression()
- sklearn -> 머신러닝 모델
9-1) 학습 - fit()
linear_model.fit(data_merge[['인구수']], data_merge[['소계']])
9-2) 학습한 값 확인
print('값1 : ',linear_model.coef_) #기울기 print('값2 : ',linear_model.intercept_) #절편- linear_.intercept_ : 절편
출력 값:

9-3) 예측하기
linear_model.predict([[6516354654],[564]])
출력 값:

'Machine Learning' 카테고리의 다른 글
| [Machine Learning] - KNN_iris분류 (0) | 2022.09.04 |
|---|---|
| [Machine Learning] - 이론 정리 (0) | 2022.09.03 |
| [Machine Learning] - 미스터리사인 (0) | 2022.09.01 |


