
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- java
- 비전공자
- lombok
- pandas
- crawling
- springboot
- SOUP
- 백준
- 크롤링
- 머신러닝
- 정처기
- request
- AWS
- BS
- regressor
- javascript
- 정보처리기사필기
- 정보처리기사
- ensemble
- dataframe
- list
- BeautifulSoup
- 웹앱
- APPEND
- Intellij
- 자바스크립트
- 자바
- pds
- Req
- sklearn
- Today
- Total
No sweet without sweat
[크롤링] - Request, Beautifulsoup 본문
1) Request 함수를 쓰기 위해서는 다른 것과 마찬가지로 import를 해와야겠죠?

* 편의상 req로 했어요
2) 들어가고 싶은 페이지 요청하기 - get

req.get("페이지")
- 여기서 주소명 작성하실 때, https:// 까지 꼭 쓰는게 중요해요!
(TMI : https:// 중 s는 securety 로 보안을 의미)
- 저는 여기서 res라는 변수에 담아줬어요
3) 요청 확인

이처럼 Response [200] 이뜨면 정상적으로 페이지를 잘 받아왔다는 것을 의미합니다.
4) 요청한 페이지의 정보를 확인 - text

문제. 다음은 멜론페이지를 열어볼거에요
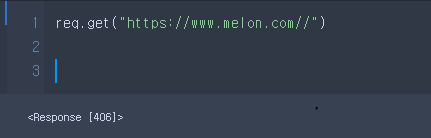
근데 Response [200]이 뜨지않고 406이 뜨네요. 이ㅣ는 응답을 할 수 없다는 것을 의미하는데요!
사용자가 아니라 컴퓨터로 인식해서 사이트에서 막은거에요.
그래서 우리가 사용자임을 홈페이지에 인식을 시켜줘야해요
먼저 , melon 홈페이지에 들어가서 F12번 눌러줘요

다음으로, Network를 누르고 F5(새로고침) 해줘요
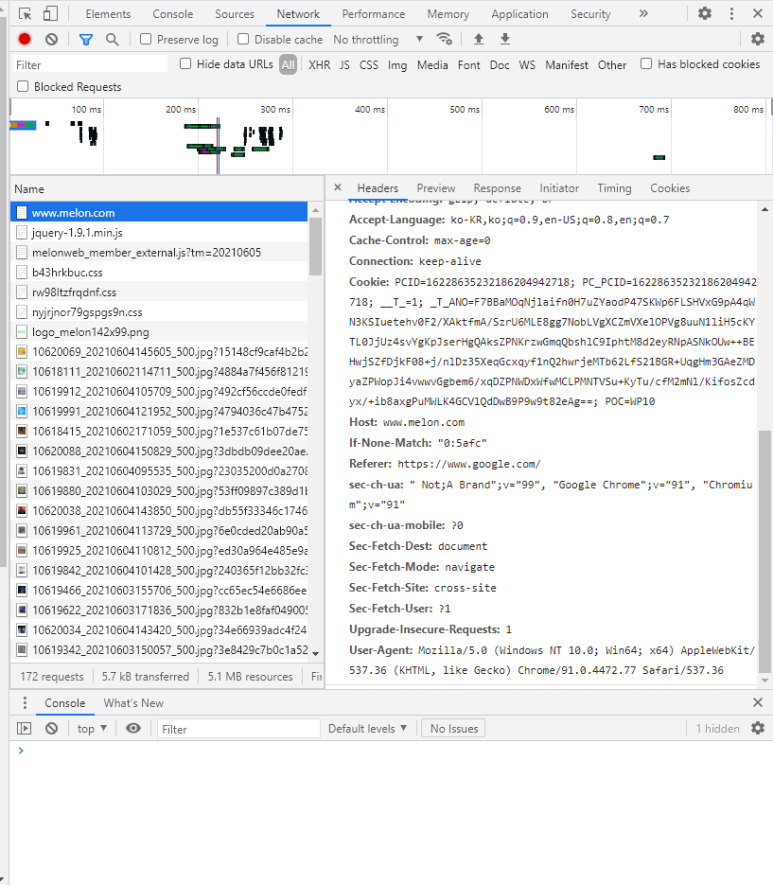
name이 www.melon.com 누르면 맨아래 User-Agent 주소가 있는데 복사를 해줘요
다시 코드로 돌아와서 저는 Dictionary 에 h변수에 넣어줄거에요! 여기서 주의
원래는 :
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
이것만 복사를 해오실텐데 {}와 ""를 아래와 같이 붙여주셔야해요
2) h = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"}

3) 그 다음으로 h라는 변수를 headers에 담아주면 끝이에요

다음으로, Beautifulsoup입니다
이는 가져온 데이터에서 내가 필요한 정보들만 추출해주는 라이브러리입니다.
1) 똑같이 import해주셔야합니다.

2) bs의 형식은 bs(어떤 데이터를 처리할 것인지, 어떻게처리할것인지('lxml')으로 구성되어있습니다.
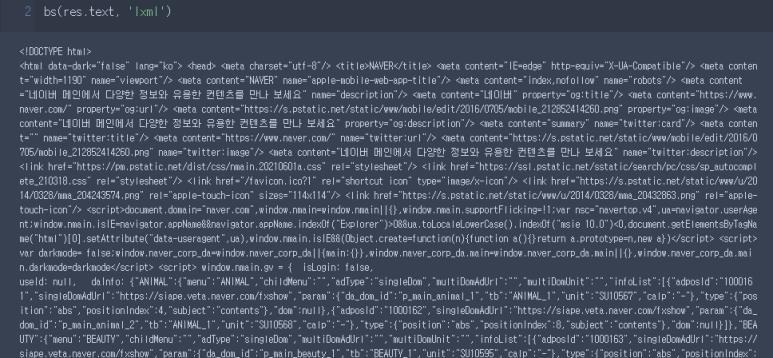
3) 데이터를 이렇게 확인하고 저는 soup라는 변수에 담아줬어요
(무조건 데이터를 확인하고 변수를 담으셔야합니다. 나중에 오류가 났을때 확인하기가 어렵습니다.)

4) 이제 soup.find_all('태그' , class_ ="") 으로 불러와주시면 됩니다.

이후 저는 result라는 변수에 담아줬습니다.
뽑아온 데이터를 보면 []에 담겨 있는데 이것을 보면 리스트임을 확인할 수 있습니다.
Q) class가 아닌 class_로 쓴 이유는 무엇일까요?
- 예약어는 변수로 사용할 수 없기에 그렇습니다.
5) 그렇다면 인덱스를 쓸수 있겠쬬?

이처럼 한개씩 뽑아올 수 있습니다.
6) 그렇다면 리스트의 전체 데이터를 조회하는 방법은 뭘까요 -> 반복문

문제1. 네이버 뉴스 타이틀만 가져오기

정답 :

'Crawling' 카테고리의 다른 글
| Gmarket top 100 가져오기 (0) | 2022.08.19 |
|---|---|
| [크롤링] - chrome driver, os, mkdir, nth-child, from urllib.request import urlretrieve (0) | 2022.08.18 |
| [크롤링] - Selenium, keys, tqdm (0) | 2022.08.17 |
| [크롤링] - append, Dataframe, csv, html 파일로 저장(멜론 TOP 100 가수) (0) | 2022.08.16 |



