
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- BS
- 정보처리기사필기
- regressor
- crawling
- 웹앱
- sklearn
- 자바스크립트
- Intellij
- pds
- 자바
- java
- ensemble
- 정보처리기사
- lombok
- 백준
- pandas
- 비전공자
- AWS
- dataframe
- request
- 크롤링
- list
- javascript
- 정처기
- 머신러닝
- springboot
- Req
- SOUP
- APPEND
- BeautifulSoup
- Today
- Total
No sweet without sweat
[Machine Learning] - KNN_iris분류 본문
1. 문제정의
- iris(붓꽃) 데이터를 활용
- 꽃잎 길이, 꽃잎 너비, 꽃받침 길이, 꽃받침 너비 4가지 특징을 통해 3가지 품종을 구분
- KNN모델의 이웃의 숫자를 조절해보자 (Hyperparameter)
2. 데이터수집 - sklearn 에서 제공하는 붓꽃 데이터 사용
1) 먼저 라이브러리 임포트
from sklearn.datasets import load_iris
2) 데이터 불러오기
load_iris()'

3) 변수에 저장
iris_data = load_iris()
4) keys 확인 .keys()

5) values 확인 .values()

6) 데이터 프레임 실제 값 확인하고 문제데이터 보기
iris_data['data']
7) 문제에 대한 정답 데이터 확인
iris_data['target']
- 정답 값이 0,1,2임을 확인할 수 있다.
8) 정답 데이터 이름 확인

0 -> setosa
1 -> versicolor
2 -> virginica
* 다른 데이터 상세 정보확인
print(iris_data['DESCR'])
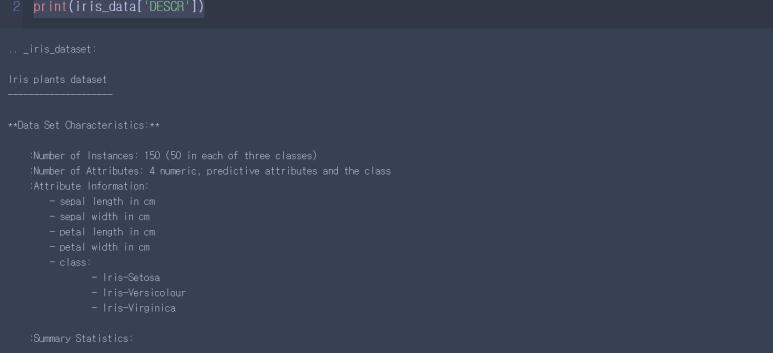
* 데이터 경로 확인
print(iris_data['DESCR'])9) numpy를 이용해 데이터프레임 가져오기
(1) 라이브러리 임포트 해오기
import numpy as np import pandas as pd
(2) Dataframe 형성하기
pd.DataFrame(np.arange(10).reshape(5,-1))
-1의 의미는 행이나 열의 개수를 보고 자동으로 행 또는 열을 맞춰주는 기능이다.
3. 데이터 전처리
1) 문제 데이터 구성하기
iris_df = pd.DataFrame(iris_data['data'], # 어떤속성값인지 알고 columns = iris_data['feature_names']) # 어떤 속성 값인지 모를 때
2) 문제, 정답 데이터로 구분하기
# 문제는 보통 2차원으로 구성되어있음 (행/열)
# 정답은 1차원으로 이루어져 있음 (백터배열은 소문자를 사용)
3) 데이터를 섞어서 나누자
- train_test_split
- X_train, X_test, y_train, y_test
random_state = 3 -> 3번 방식으로 Data 섞어주는 기능
test_size = 몇퍼센트로 섞겠다.
(1) 라이브러리 임포트
from sklearn.model_selection import train_test_split
(2) 데이터 나누기
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state = 3, test_size = 0.3) # 퍼센트
(3) X_train

(4) y_train

4. 탐색적 데이터 분석
- 우선 skip
5. 모델 선택 및 하이퍼파라미터 튜닝
- knn 모델 받아오기
knn = KNeighborsClassifier()
6. 학습
# X_train : 문제_훈련용
# y_train : 정답_훈련용
knn.fit(X_train,y_train)
7. 평가
# 예측 점수 : score(X_test,y_test)
# score는 정확도를 통해서 점수를 나타내줌
# X_test를 통해서 예측값을 출력하다
# 실제정답인 y_test와 비교를 해 점수를 나타내줌
knn.score(X_test,y_test)

----------------------------------
문제 변형
1. 이웃의 수 변경
knn3 = KNeighborsClassifier(n_neighbors=3)2. 학습하기
knn3.fit(X_train, y_train)3. 점수확인
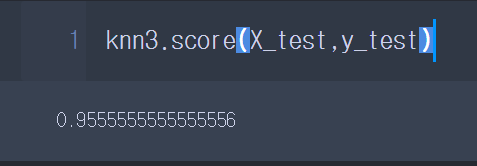
----------------------------------
문제 변형 : 하이퍼 파라미터(n_neighbors)에 변화를 주면 scoreㄱ밧에 어떤 변화가 있는지 확인해보자

# test testList = [] for k in range(1,101):
model2 = KNeighborsClassifier(n_neighbors=k) model2.fit(X_train,y_train) #학습 = 훈련
testList.append(model2.score(X_test,y_test))
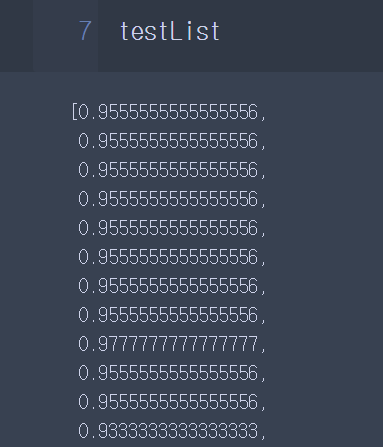
시각화
plt.figure(figsize=(25,5)) # 출력할 그래프의 크기
plt.plot(range(1,101), # X데이터 = 1~100 train_list, # y데이터 c= 'red')
plt.plot(range(1,101), # X데이터 = 1~100 testList, # y데이터 c= 'blue')
plt.xticks(range(1,101))
plt.grid() # 기준선 plt.show()

# 최적의 이웃 수 : 9, 13, 17
knn_model = KNeighborsClassifier(n_neighbors=9, p = 1, weights='distance')
knn_model.fit(X_train,y_train)
점수확인 :
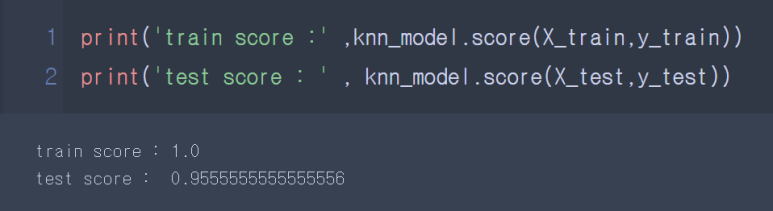
train/test_list에 저장된 학습값 확인하기


예측 :

'Machine Learning' 카테고리의 다른 글
| [Machine Learning] - 이론 정리 (0) | 2022.09.03 |
|---|---|
| [Machine Learning] - 서울시 구별 CCTV 현황 분석하기 (numpy, pandas, matplotlib.pyplot) (0) | 2022.09.02 |
| [Machine Learning] - 미스터리사인 (0) | 2022.09.01 |


