
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- javascript
- sklearn
- request
- lombok
- regressor
- Req
- 자바스크립트
- BS
- SOUP
- ensemble
- APPEND
- list
- 정보처리기사필기
- pds
- pandas
- dataframe
- 정보처리기사
- AWS
- 크롤링
- 정처기
- crawling
- 백준
- java
- 비전공자
- springboot
- 웹앱
- Intellij
- 자바
- BeautifulSoup
- 머신러닝
- Today
- Total
No sweet without sweat
[크롤링] - chrome driver, os, mkdir, nth-child, from urllib.request import urlretrieve 본문
[크롤링] - chrome driver, os, mkdir, nth-child, from urllib.request import urlretrieve
Remi 2022. 8. 18. 17:54문제 1.
1) 크롬드라이브를 실행해서 유튜브 화면 실행
2) 영상의 제목만 크롤링하기
3) 영상의 길이를 확인, 순수한 텍스트까지 출력
1) 구글에 크롬드라이버 검색
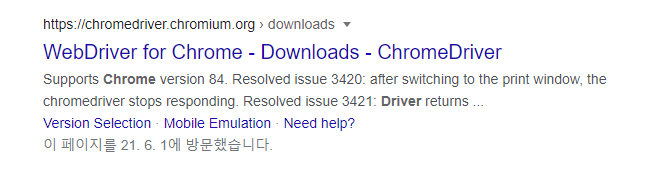
눌러서 자신에 맞는 버젼의 크롬을 다운로드 받으시면 됩니다.

자신의 크롬버젼 확인 설정에서 chrome정보를 누르면 본인의 버젼을 확인할 수 있습니다.
확인 후 본인이 하고 있는 폴더에 그대로 넣어주시고 실행해주시면 됩니다.
2)
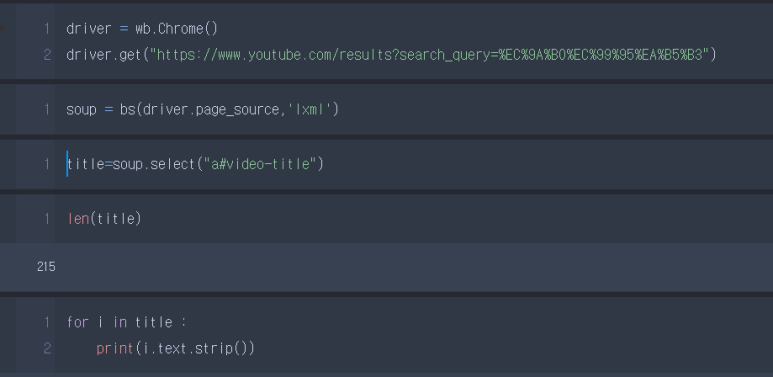
항상 len으로 길이 확인해주는 습관을 형성해주는 것이 좋아요
저는 우왁굳님 검색했습니다.

한솥에서 더보기 클릭한 것처럼 페이지를 내려서 더 많은 유튜브영상을 볼 수 있께 해놓으면 더 많은 데이터를 가져올 수 있습니다.
그러기 위해서 페이지를 내려야합니다

html 구성상 body 여서 tag_name으로 잡아서 send_keys로 페이지다운을 보내주었습니다. 이렇게되면 한번만 작동이 되기에 반복적으로 내릴 수 있도록 반복문을 실행하였습니다.
3) 조회수 크롤링

조회수만 가져오고 싶은데 영상올린 년도도뜨네요
왜, 그러나 확인했는데
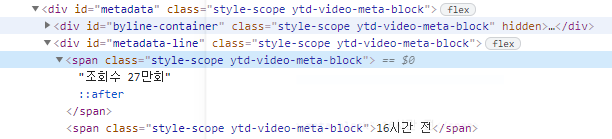
span으로 같이 묶여있어서 이런 상황이 발생합니다.
이렇게 아이디같이 구분태그가 없을경우 nth-child(얻고자하는 정보)를 통해 원하는 데이터만 뽑아올 수 있습니다.

문제 2. 이미지 크롤링
1) import

이처럼 os는 파일시스템을 위한 라이브러리
from urllib.request import urlretrieve 는 이미지 경로를 파일로 만들어줍니다.
2) 이미지 끌어오기전 폴더 생성

- 저는 바탕화면에 폴더를 만들었고 본인이 만들고 위치에 만들면 됩니다.
os.path.isdir("경로")
os.mkdir("폴더명"){mkdir -> makedirectory)
3) 웹사이트 열고 정리된 형식으로 보여주기

4) 이미지 가져오기

이미지의 클래스명을 자세히보면 _image _listImage 사이에 한칸 띄어져있는데 이럴경우 ' . ' 을 붙여주셔야 합니다.

우리가 가져오고 싶은 것은 text가 아니라 img정보이기에 'src'정보만 끌어와야합니다.
5) src정보만 가져오기

6) 반복문을 통해 여러개의 사진 끌어올 준비하기
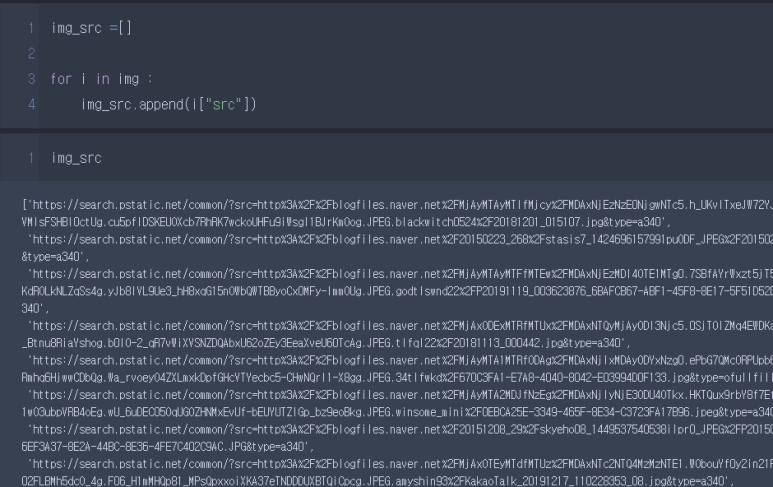
저는 149개의 데이터를 가져왔네요

7) 사진 저장하기 - tqdm 사용
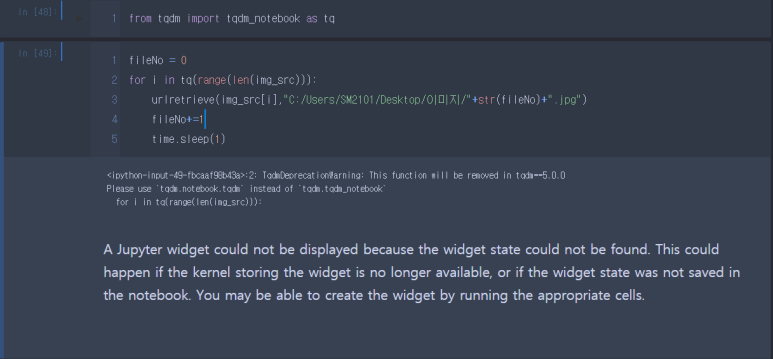
Fileno 에 +1값을 게속 주면서 이미지 저장하고자해서
fileno 변수를 우선 만들었습니다.
그리고 len값으로 찾은 이미지만큼 넣고자 했습니다.
urlretrieve(이미지(src),"저장경로","이미지이름"+".파일명")
이미지 이름에 string으로 묶어줬습니다.(현재 string+int+string)
'Crawling' 카테고리의 다른 글
| Gmarket top 100 가져오기 (0) | 2022.08.19 |
|---|---|
| [크롤링] - Selenium, keys, tqdm (0) | 2022.08.17 |
| [크롤링] - append, Dataframe, csv, html 파일로 저장(멜론 TOP 100 가수) (0) | 2022.08.16 |
| [크롤링] - Request, Beautifulsoup (0) | 2022.08.15 |



